
1. 회귀 소개
- 회귀는 현대 통계학을 받치고 있는 주요 기둥 중 하나
- 회귀는 여러 개의 독립변수(특성)와 한 개의 종속변수(타겟, y) 간의 상관관계를 모델링하는 기법을 통칭
- 회귀에서는 클래스라고 부르지 않음
- 머신러닝 회귀 예측의 핵심은 주어진 피처와 결정 값 데이터 기반에서 학습을 통해 최적의 회귀 계수를 찾아내는 것
- 회귀는 회귀 계수의 선형/비선형 여부, 독립/종속변수의 개수에 따라 여러가지 유형으로 나눌 수 있음
- 회귀에서 가장 중요한 것은 회귀 계수. 회귀 계수의 결합이 선형인지 아닌지에 따라 선형 회귀와 비선형 회귀로 나눔
- 독립변수가 한 개인지 여러 개인지에 따라 단일/다중 회귀로 나눔
- 단일 회귀는 거의 등장하지 않음
- 지도학습은 두 가지 유형
- Classification(분류)
- 카테고리값
- 이산값
- 0, 1, 2 -> 답을 정확하게 맞췄는지 비교 가능
- accuracy 평가 가능
- Regression(회귀)
- 연속값
- 숫자값
- 집값, 토익 성적, 기대 키
- 오차 평균이 적으면 적을수록 잘 맞췄다고 평가
- MSE, RMSE, MAE 가 대표적으로 사용됨
- 가장 많이 사용되는 선형 회귀는 실제값과 예측값의 차이(오류의 제곱값)를 최소화하는 직선형 회귀선을 최적화하는 방법
- 선형 회귀 모델을 규제 방법에 따라 다시 별도의 유형으로 나뉠 수 있음
- 규제는 일반적으로 선형회귀의 과적합 문제를 해결하기 위해 회귀 계수에 패널티 값을 적용하는 것
- 일반 선형 회귀 : 예측값과 실제값의 평균제곱오차를 최소화할 수 있도록 회귀계수를 최적화, 규제 적용 안함
- 릿지 : 일반 선형 회귀에 L2 규제 적용. 상대적으로 큰 회귀 계수 값의 영향도를 감소시키기 위해 회귀 계수값을 더 작게 만든는 규제 모델
- 라쏘 : 선형 회귀에 L1 규제를 적용. 예측 영향력이 작은 피처의 회귀계수를 0으로 만들어 회귀 예측 시 피처가 선택되지 않게 하는 것
- 엘라스틱넷 : L1, L2 규제가 결합된 모델. 주로 피처가 많은 데이터세트에 적용됨
- 로지스틱 회귀 : 이름은 회귀지만 분류에서 사용되는 선형 모델
2. 단순 선형 회귀
- 독립변수도 하나 종속변수도 하나
- 잔차 : 실제값과 예측값의 오차
- 최적의 회귀 모델을 만드는 것 : 전체 데이터의 잔차 합이 최소가 되는 모델을 만든다는 의미
- 오류값의 합이 최소가 될 수 있는 최적의 회귀 계수(절편과 기울기)를 찾는 것이 목표
- 오류의 합을 계산할 때는 MAE(절대값), MSE(평균 제곱)를 취함
3. 경사 하강법(Gradient Descent) 비용 최소화하기
- RSS 비용 함수를 최소화하는 방법으로 직관적으로 제공
- 데이터를 기반으로 '알고리즘이 스스로 학습한다'는 머신러닝 개념을 가능하게 만들어준 핵심 기법
- 점진적으로 반복적인 계산을 통해(기울기가 최소가 될 때까지 반복) W(기울기)파라미터 값을 업데이트하면서 오류값이 최소가 되는 파라미터 W를 구하는 방식
4. 사이킷런 LinearRegression을 이용한 보스턴 주택 가격 예측
- LinearRegression 클래스는 예측값과 실제값의 RSS(잔차제곱합)를 최소화해 OLS 추정 방식으로 구현
5. 다항 회귀와 과대적합/과소적합 이해
다항 회귀 이해
- 지금까지 설명한 회귀는 독립변수와 종속변수의 관계가 일차방정식 형태로 표현된 회귀
- 직선으로 표현할 수 없는 관계를 다항(Polynomial) 회귀를 통해 나타낼 수 있음
- 다항회귀는 단항식이 아닌 2차, 3차 방정식과 같은 다항식으로 표현
- 다항회귀는 선형회귀임
- 사이킷런 PolynomialFeatures 클래스를 통해 피처를 다항식 피처로 변환
- PolynomialFeatures 클래스는 degree 파라미터를 통해 입력 받은 단항식 피처를 degree에 해당하는 다항식 피처로 변환
다항회귀를 이용한 과소적합 및 과적합 이해
- 다항 회귀는 피처의 직선 관계가 아닌 복잡한 다항 관계를 모델링할 수 있음
- 다항식의 차수가 높아질수록 매우 복잡한 피처 간의 관계까지 모델링 가능
- 다항회귀의 차수를 높일수록 학습데이터에만 맞춘 학습이 이뤄져서 정작 일반적인 환경(테스트 데이터)에서는 정확도가 떨어진다
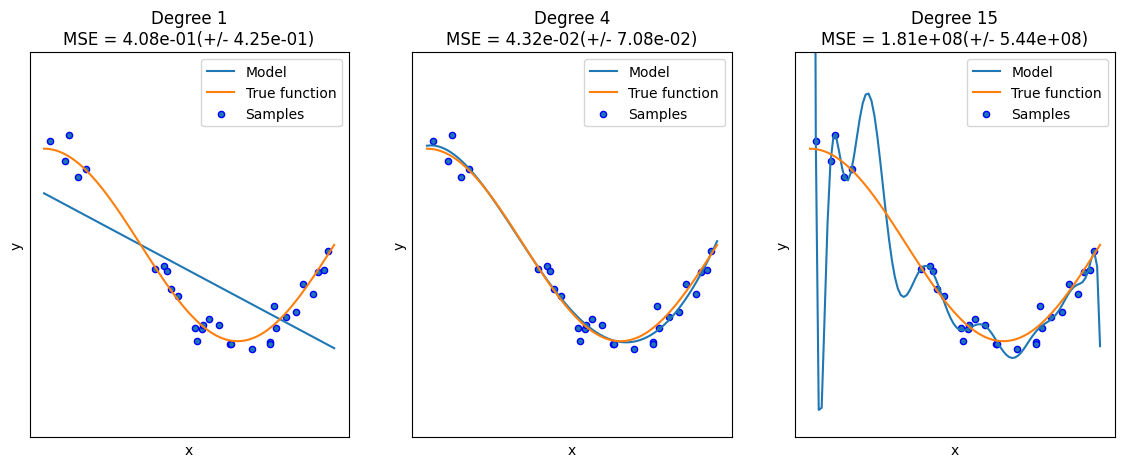
-> degree=1 : 단순 직선. 단순 선형 회귀와 같음
-> 예측 곡선이 학습 데이터 패턴 반영 못함. 과소적합
-> degree=4 : 실제 데이터세트와 유사한 모습
-> MSE 값 약 0.04로 가장 뛰어난 예측 성능
-> degree=15 : 15차 방정식
-> 복잡한 곡선이 그려짐
-> 거의 모든 x(학습데이터)를 정확히 예측하지만 새로운 x(테스트 데이터)가 들어오면 맞추지 못함
-> 과적합
편향-분산 트레이드오프
- 편향이 높아지면 분산은 낮아지고, 분산이 높아지면 편향이 낮아짐
- 분산 : 예측한 값의 범위
- degree=1 과 같은 모델은 매우 단순화된 모델. 지나치게 한 방향성으로 치우친 경향이 있음. 고편향성을 가짐. 분산 작음(좁은 범위)
- degree=15 데이터 하나하나의 특성을 반영하는 매우 복잡한 모델. 높은 변동성을 갖는 모델 -> 고분산성을 가짐.
- 고편향/고분산 = 과적합
- 저편향/고분산(편향은 높으나 분산이 적다) = 과소적합
- 저편향/저분산 = 예측 결과가 실제 결과에 매우 근접하면서 예측변동이 크지 않고 특정 부분에 집중되어 있는 아주 뛰어난 성능
6. 규제 선형 모델 - Ridge, Lasso, Elasticnet
- 회귀모델은 적절히 데이터에 적합하면서 회귀계수가 기하급수적으로 커지는 것을 제어할 수 있어야함
- 비용함수는 학습데이터의 잔차 오류를 최소로 하는 손실 최소화 방법(RSS)과 과적합 방지를 위해 회귀 계수 값(가중치 값)이 커지지 않도록 하는 방법이 균형을 이뤄야함
- 회귀계수의 크기를 제어해 과적합을 개선하려면 비용(Cost) 함수의 목표가 변경될 수 있음
- -> L1, L2 규제 함수 사용
- 오차의 거리를 구하는 공식에 따라 나뉨
- l1(Lasso) : 맨하튼 노름(x, y 좌표 간격 이동 길이)
- l2(Ridge) : 유클리드 노름(대각선 길이)
- alpha값(규제의 강도)에 따른 w(회귀계수)의 변화
- Ridge는 alpha값이 커지면 회귀계수가 작아짐. 관련이 없는 특성들의 가중치 절댓값 합(=회귀계수의 합)이 0에 가깝게 만듦
- Lasso는 관련이 없는 특성들의 가중치(=회귀계수)를 0으로 만들어서 제거. 특성을 덜 사용함
- 최적 기울기를 찾지 않음. 못 찾게 방해 -> 오버피팅을 막기 위한 공부 방해
Ridge 회귀
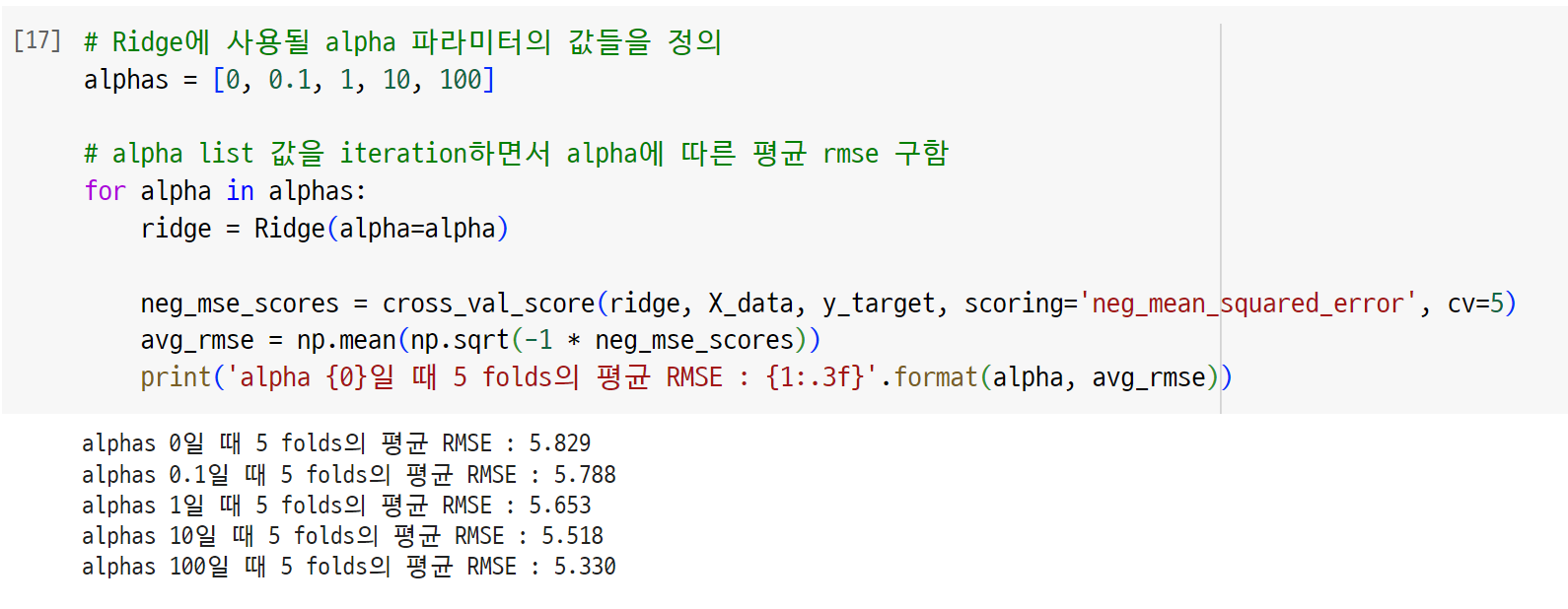
- alpha=0일 때 최적의 직선
- alpha가 클 때 rmse 성능이 더 좋게 나옴
- 1)의 경우 최적의 직선이 아니라 과적합이었던 것
# alpha에 따른 회귀계수값(가중치) 시각화
fig, axs = plt.subplots(figsize=(18,6), nrows=1, ncols=5)
# alpha에 따른 회귀계수값을 저장하기 위해 빈 데이터프레임 생성
coeff_df = pd.DataFrame()
# alpha 리스트값을 차례로 입력, 회귀계수값 시각화, 데이터 저장
# pos는 axis의 위치 지정
for pos, alpha in enumerate(alphas):
ridge = Ridge(alpha = alpha)
ridge.fit(X_data, y_target)
coeff = pd.Series(data=ridge.coef_, index=X_data.columns)
colname = 'alpha'+str(alpha)
coeff_df[colname] = coeff
coeff = coeff.sort_values(ascending=False)
axs[pos].set_title(colname)
axs[pos].set_xlim(-3,6)
sns.barplot(x=coeff.values, y=coeff.index, ax=axs[pos])
plt.show()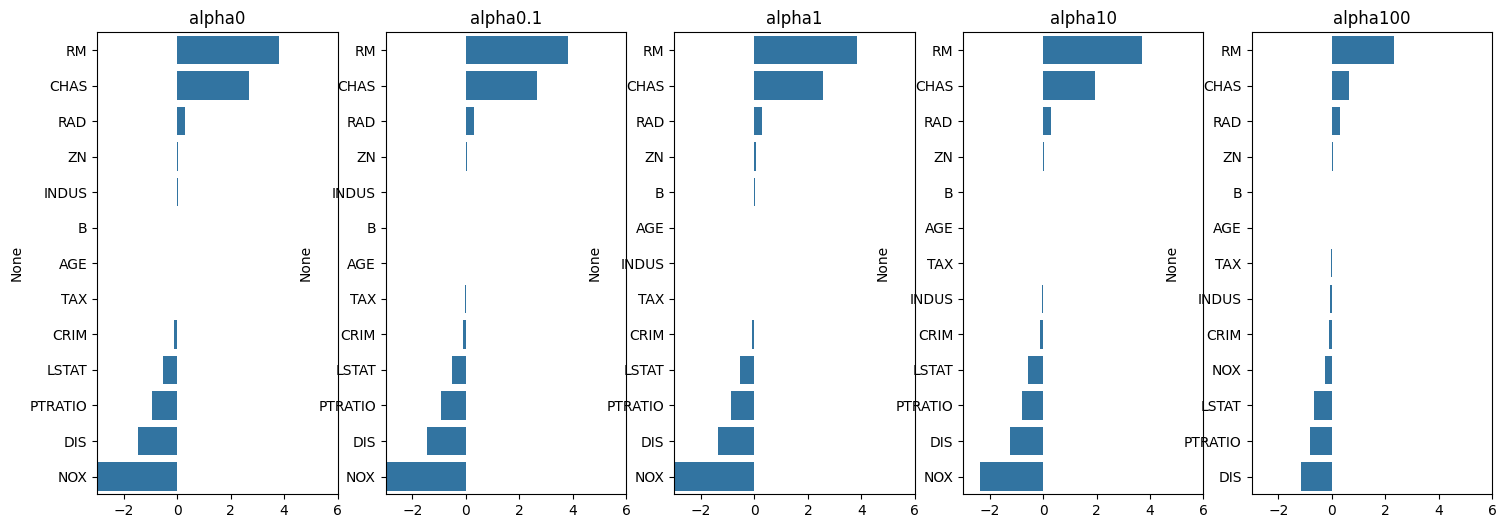
- alpha 값이 커질수록 RM이 0에 가까워짐
- Ridge 회귀는 관련없는 특성의 회귀계수를 0에 가깝게 만든다
Lasso 회귀
- L1 규제
- 불필요한 회귀계수(가중치)를 급격하게 감소시켜 0으로 만들어 제거 -> 예측에 전혀 사용하지 않음
- L1 규제는 적절한 피처만 회귀에 포함시키는 피처 선택의 특성을 가지고 있음

-> alpha가 낮아질 수록 RMSE 낮아짐
# alpha에 따른 회귀계수값(가중치) 시각화
fig, axs = plt.subplots(figsize=(18,6), nrows=1, ncols=5)
# alpha에 따른 회귀계수값을 저장하기 위해 빈 데이터프레임 생성
coeff_df = pd.DataFrame()
# alpha 리스트값을 차례로 입력, 회귀계수값 시각화, 데이터 저장
# pos는 axis의 위치 지정
for pos, alpha in enumerate(lasso_alphas):
lasso = Lasso(alpha = alpha)
lasso.fit(X_data, y_target)
coeff = pd.Series(data=lasso.coef_, index=X_data.columns)
colname = 'alpha'+str(alpha)
coeff_df[colname] = coeff
coeff = coeff.sort_values(ascending=False)
axs[pos].set_title(colname)
axs[pos].set_xlim(-3,6)
sns.barplot(x=coeff.values, y=coeff.index, ax=axs[pos])
plt.show()
- Lasso는 불필요한 특성의 가중치(회귀계수)를 0으로 만들어서 제외
- alpha값이 커질수록 가중치가 없어짐
- 필요한 가중치도 0으로 줄어드는 문제
- 이를 해결하기 위해 L1, L1 규제를 합친 Elastic Net Regression
Elastic Net Regression
- L2 규제를 Lasso 회귀에 추가
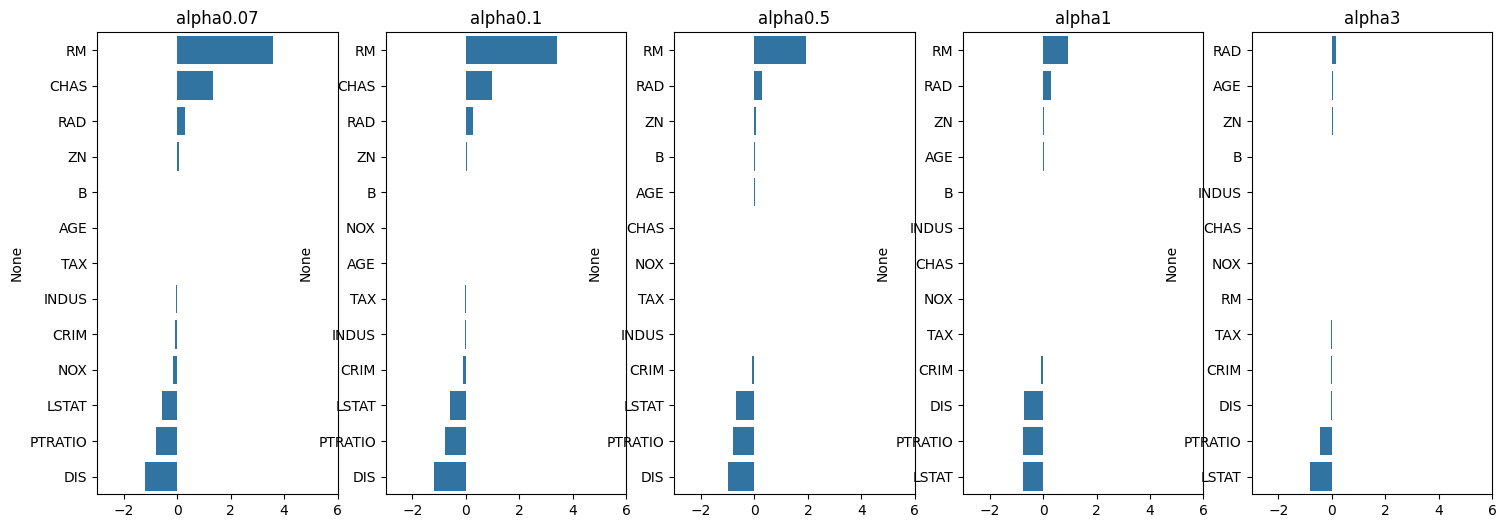
- lasso와 마찬가지로 피처의 가중치가 0에 가까워지지만 가까워지는 속도가 lasso보다 느림
- 많은 파라미터를 돌려봐야 어떤 모델이 최적인지 알 수 있음
선형회귀 모델을 위한 데이터변환
- 선형회귀는 피처와 타겟(라벨) 간에 선형관계가 있다고 가정하고 최적의 선형함수를 찾아 예측
- 타겟값의 분포가 가우시안 정규분포 형태인 것을 선호
- 타겟값과 피처값의 분포가 어느 한쪽으로 치우친 왜곡형태의 분포일 경우 예측 성능에 부정적인 영향
- 따라서 일반적으로 선형회귀를 사용할 경우 학습 전 데이터셋에 정규화/스케일링 작업 선행
일반적으로 피처 데이터셋과 타겟데이터셋은 스케일링/정규화 방법이 다르다
- 피처데이터셋 스케일링/정규화
- StandardScaler로 평균0 분산1인 정규분포 데이터셋으로 변환 혹은 MinMaxScaler 이용해 최소값0 최대값1인 데이터로 정규화
- 스케일링/정규화한 데이터셋에 다시 다항 특성(곡선)을 적용하는 방법-> 보통 1을 수행하고 성능에 향상이 없을 경우 사용. 과적합 위험이 큼
- 원본데이터값에 log를 취함으로써 정규분포에 가까운 형태로 값이 분포됨. log Transformating. 선형회귀에서 많이 사용됨
- 타겟데이터셋 스케일링/정규화
- StandardScaler와 log Transformating을 사용할 수 있음. 보통 log Transformating를 많이 사용
- StandardScaler -> x 표준편차, x 평균을 정확히 모를 경우 원래값으로 되돌리기 어려움
- log Transformating -> log 변환만 하면 원래값으로 돌아감
- 이론적으로는 StandardScaler를 사용하는 것이 가장 결과가 좋지만(표준정규분포를 따르므로)
- 이 케이스는 MinMax를 사용했을 때 RMSE가 가장 낮았(=오차가 가장 적었)다.
- 데이터세트마다 다른 결과가 나올 수 있음
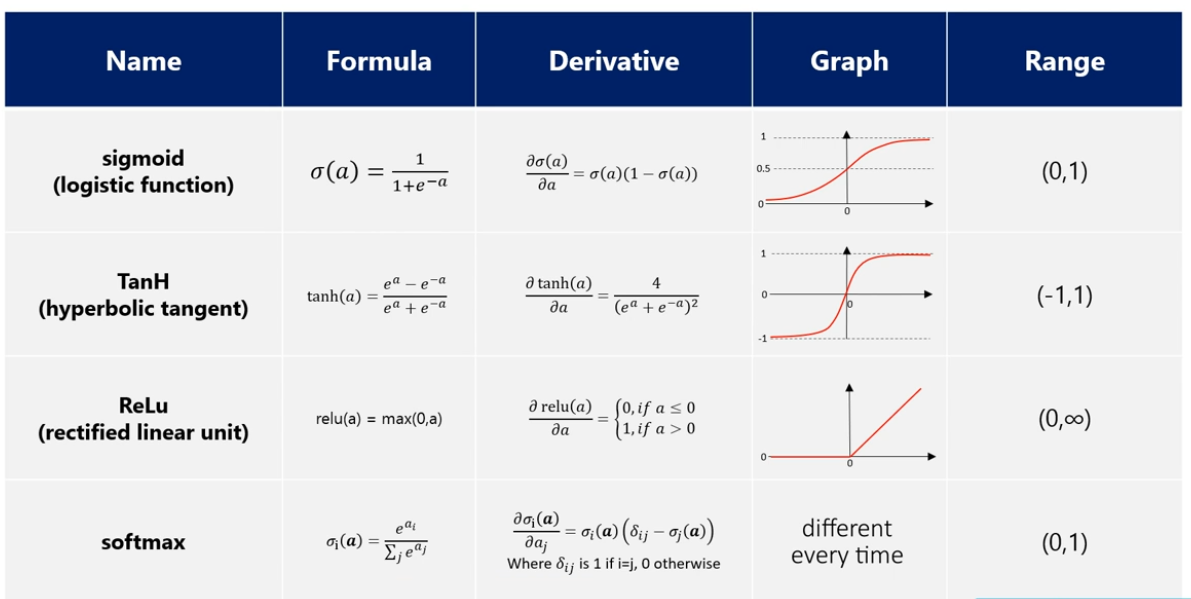
활성화 함수
- sigmoid
- 0 ~ 1
- Logistic Regression
- TanH
- ReLU
- softmax
8. 회귀 트리
- 분류에서 사용하는 모델을 살짝 변형해서 회귀에서도 사용함
- sigmoid = ax+b
- 트리 기반 회귀는 회귀 트리를 이용하는 것
- 회귀를 위한 트리를 생성하고 이를 기반으로 회귀 예측
- 일반적으로 분류모델에서 학습한 분류 트리와 큰 차이는 없음
- 다만 리프노트에서 예측 결정값을 만드는 과정에서만 차이 존재
- 분류트리에서 특정 클래스 레이블을 결정했다면 회귀트리는 리프노트에 있는 데이터의 평균값을 구하여 회귀값을 예측
- 산점도 그래프에서 구간을 기준으로 분할
- X값의 균일도를 반영한 지니계수에 따라 분할함
- 리프노드 생성 기준에 부합하는 트리 분할이 완료되면 리프노드에 소속된 데이터의 평균값을 구해 최종적으로 리프노드에 결정값으로 할당 -> 회귀값으로 예측
- 사이킷런에서 제공하는 회귀 기반 클래스
- DecisionTreeRegressor
- GradientBoostingRegressor
- XGBRegressor
- LGBMRegressor
fig , (ax1, ax2, ax3) = plt.subplots(figsize=(14,4), ncols=3)
# 선형회귀와 결정트리회귀 예측선 시각화
# 선형회귀 학습모델 회귀 예측선
ax1.set_title('Linear Regression')
ax1.scatter(bostonDF_sample['RM'], bostonDF_sample['PRICE'], c='darkorange')
ax1.plot(X_test, pred_lr, label='linear', linewidth=2)
# DecisionTreeRegressor: max_depth=2 학습모델 회귀 예측선
ax2.set_title('Decision Tree Regressor: \n max_depth=2')
ax2.scatter(bostonDF_sample['RM'], bostonDF_sample['PRICE'], c='darkorange')
ax2.plot(X_test, pred_dt2, label='max_depth:2', linewidth=2)
# DecisionTreeRegressor: max_depth=7 학습모델 회귀 예측선
ax3.set_title('Decision Tree Regressor: \n max_depth=7')
ax3.scatter(bostonDF_sample['RM'], bostonDF_sample['PRICE'], c='darkorange')
ax3.plot(X_test, pred_dt7, label='max_depth:7', linewidth=2)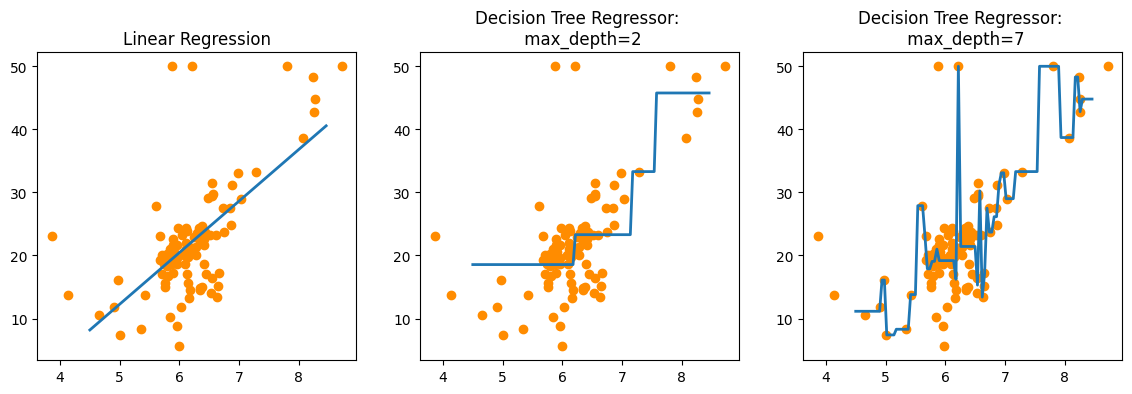
- 트리 기반 회귀 모델은 데이터 구간을 기준으로 분할하고
- 해당 구간 데이터의 평균값을 구해서 회귀값을 예측함
- max_depth=7인 Decision Tree Regressor 모델 -> 과적합 발생
멋사 AIS 7기를 끝낸 후 호주에 1년간 지내면서 많은 것들을 까먹었다. 이 과정을 들으면서 머신러닝을 다시 공부하고 있다. 이미 써봤던 데이터로 비슷한 모델을 만드는 게 약간 지루할 때도 있었는데 확실히 헷갈리던 개념으로 들어오니까 두 번 공부하는 게 도움이 된다. 멋사 강의를 들을 때는 지식에 두들겨 맞는 수준이었다. 매주 목요일마다 복습 페이지를 노션에 작성하면서도 어떤 것들은 둥둥 떠다니는 느낌이었다. 코드를 짜기다가 이게 어떤 모델인지 어떤 파라미터인지 날아가버릴 때가 있었는데, 이번에 수업을 들으면서 다시 개념들을 정리하고 있다. 함수를 주르르 작성하는 건 아직 엄두가 안 나지만 예제 코드 해석은 할 수 있는 수준이 됐다. 모쪼록 꾸준히 공부해서 취업의 결실을 맺을 수 있길.
'데이터분석 공부 > DSBA 4기' 카테고리의 다른 글
| 순환 신경망(Recurrent Neural Network, RNN) (0) | 2024.04.22 |
|---|---|
| 16/04/24 TIL 딥러닝 컨볼루션 신경망, 과대적합 방지, 전이 학습, 파인 튜닝 (0) | 2024.04.16 |
| 21/03/24 TIL (앙상블 학습, Voting, Bagging, Boosting, Random Forest, GBM, XGBoost, LightGBM) (0) | 2024.03.22 |
| 20/03/24 TIL(KNN 알고리즘, 서포트 벡터 머신) (0) | 2024.03.20 |
| 19/03/2024 TIL (0) | 2024.03.20 |